
From Email Poem to 3-Minute Cinematic Piece
Sometimes a project begins with ambition.
Sometimes it begins with almost nothing.
“Invisible Paths” started with two lines in an email.
Anna and I were simply trading lines of poetry back and forth — no discussion of theme, no planning, no attempt to steer the direction. One person would write two lines and send them. The other would reply with two more.
That was the entire “method.”
No outline.
No goal.
Just curiosity and rhythm.
What emerged surprised both of us. A quiet mystical arc appeared on its own, almost as if the poem already existed and we were just uncovering it line by line.
Here is the poem exactly as it formed.
Invisible Paths
Hands move without thinking, tracing invisible paths. You follow them, curious where they lead.
Is there a map leading our journey?
Floating up in a hot-air balloon — we see the horizon.
Closed eyes. Gentle breezes. Clear, crisp air cleansing the senses.
Deep breaths as we let go. Let it all go. Eyes open, bright, ready to see.
Thin air, high altitude. The curvature of the earth. What catches my eye?
A bright shining light. Mind on fire. Curious and free.
Clarity as I descend, layer after layer.
Heavens. Sun. Clouds. Sky. Tippy tops. Cacophony. Earth. Me.
When Anna’s final lines arrived, the piece felt complete.
The journey outward returned to the self.
There was no need to force a tidy conclusion or a sentimental “we.” The restraint actually strengthened the ending.
Once the poem landed, the next impulse wasn’t revision.
It was translation.
Poem → sound → vision.
Turning a Poem into Music
The musical direction came almost immediately: progressive rock with a cinematic feel. Think the atmospheric side of the 1970s — expansive arrangements, emotional builds, and a sense of journey.
The poem’s natural shape already matched the classic progressive structure:
quiet beginning → gradual ascent → cosmic expansion → reflective descent → intimate ending.
The music generator was given a single descriptive prompt written by ChatGPT to my specification to capture that arc:
arpeggiated guitar, ambient synth pads, layered Mellotron strings, dynamic bass, cinematic drums, male lead vocal with occasional falsetto, female harmony vocals, ethereal reverb, reflective and soaring mood, progressive-rock concept, build from quiet introspection to cosmic lift then gentle descent, intimate landing
The result was a 2:38 minute musical piece. That was created in Producer.ai after 12 iterations.
Using LALAL.AI, the stems were split and the generated vocals were partially discarded to create open space for the narrated poem to be layered over instrumental soundtrack.
Voiceover
For narration I used the voice Francesca Segretto from ElevenLabs.
The opening lines of the poem were trimmed so the narration begins during the balloon ascent sequence. The final spoken track runs about sixty seconds.
The audio was then divided locally in Audacity into six ten-second clips so each could be lip-synced separately.
This turned out to be important later.
Building the Visual World
The central image for the film appeared early: a hot-air balloon covered in chandelier crystals. Sunlight passing through the crystals refracts into rainbow light, giving the whole sequence a quiet dreamlike shimmer.
Still images were generated with Midjourney.
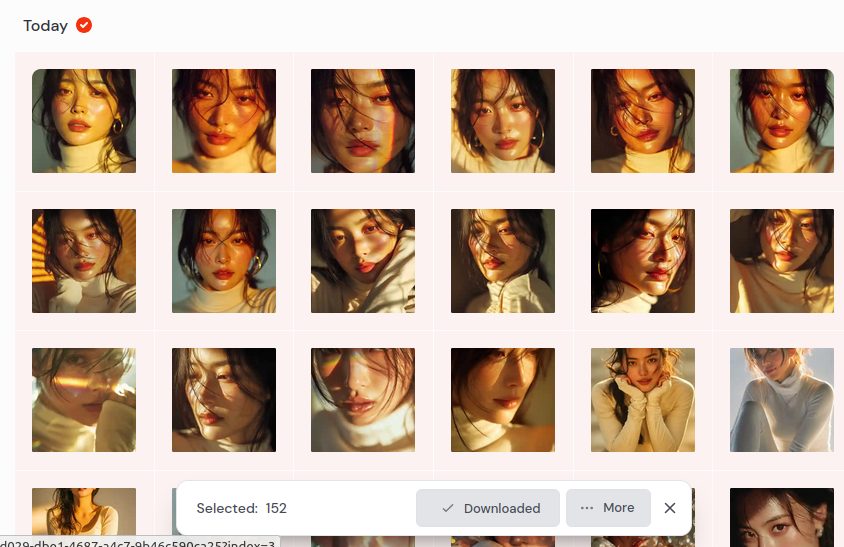
The recurring character is a modestly-dressed young Chinese woman — calm, curious, quietly present — traveling through the balloon ascent and the later atmospheric scenes.
AI image generation always involves heavy filtering. Out of 153 generated images:
- 27 were discarded for bare midriffs
- 35 for excessive cleavage or exaggerated anatomy
- several for classic AI hallucinations (extra arms, distorted hands)
MIdjourney AI when left to it’s own accords puts too much bare skin into female images. This is because it is governed by popularity as truth.

About 87 images survived the first pass.
From those, 36 stills were selected for the final sequence. And then later culled down to 20 for conversion to video clips using Grok Imagine.
One practical lesson: negative prompts matter more than you think. If I had started with strong exclusions like
--no cleavage, no bare midriff, no crop top, no extra arms, no distorted anatomy
I would have saved a lot of time.

PROMPT
Medium shot, hot-air balloon covered with chandelier crystals, refracting sunlight like a prism descending, female Chinese fitness model, ~28 years old, modestly dressed in soft ivory long-sleeve top and light gray fitted leggings, simple flat shoes, long dark hair gazing up at crystals with hands raised, peaceful and uplifted mood, fantasy cinematic style, natural morning lighting, soft warm tones, 35mm lens
Lip-Sync Experiments
Lip-sync was done with WAN Video AI.
The first attempts failed completely.

Full-body or medium-distance shots produced no mouth movement at all. The model prioritized body motion instead of speech tracking.
The fix was simple but unintuitive: switch to extreme close-ups.

Faces had to fill roughly 60 to 80 percent of the frame for the system to track the mouth reliably. Once that adjustment was made, the six narration clips rendered successfully as talking-head shots.
WORKAROUND: Well, almost all talking-heads were WAN AI. I ran out of WAN credits on the last image. I didn’t want to buy more for one image. So I used a free convertor which allowed enough free credits to produce one single image-audio video. It was watermarked with their name in the corner (17 minute render time). I then used: ezremove.ai to eliminate that “blemish.” Done.
Each WAN render cost about $0.90 and took roughly three minutes to process. Failed renders aren’t refundable, which makes experimentation slightly painful but still manageable. I’m shopping for alternatives.
Final Assembly
Editing was done in Kdenlive on Linux Mint operating system.
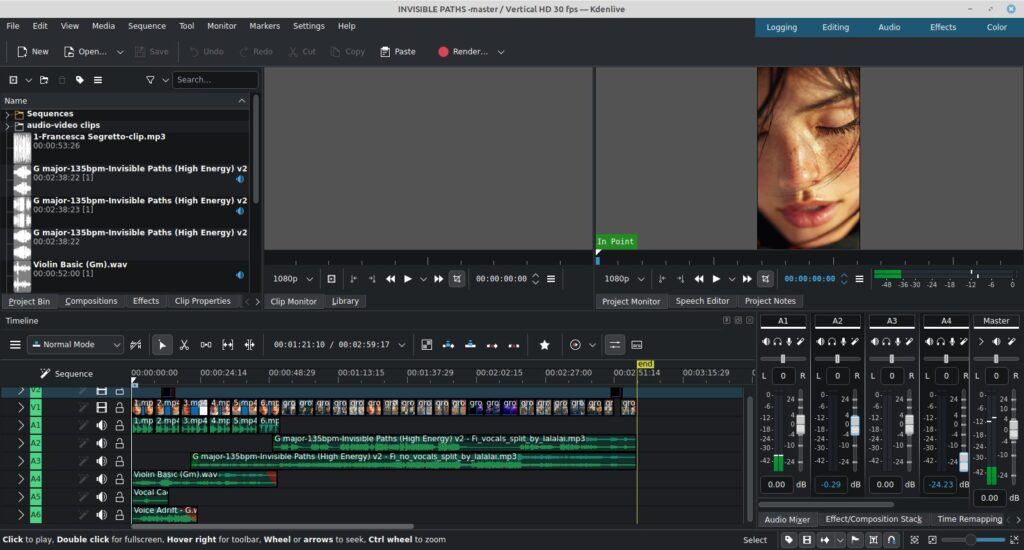
The structure ended up very simple:
- 6 lip-sync narration clips (10 seconds each)
- 20 silent atmospheric visuals (6 seconds each)
Total runtime: almost exactly three minutes.
The music soundtrack track was trimmed slightly. Three free key-of-G tonal pads from Multiply Sound transitioned the introduction to land precisely under the visual timeline.
The Real Lesson
The interesting part of this project isn’t the software.
It’s the origin.
The entire piece grew from tiny, low-pressure exchanges: two lines at a time, no hierarchy, no expectations.
That kind of rhythm creates space for intuition. Instead of forcing meaning, you simply respond to what arrives.
Then, once the seed exists, the creative work becomes translation. Words become sound. Sound becomes image.
Today’s tools make that translation surprisingly accessible. But the real bottlenecks are still human:
- patience with iteration
- discipline with prompts
- tolerance for failure
- knowing when to stop adding
Most important of all: trust the small beginning.
If you want to awaken creative confidence in someone — or in yourself — start with something almost trivial.
Send someone two lines of poetry.
Ask them to reply with two more.
Then follow the thread wherever it leads.
Invisible paths rarely appear until you start walking them.
Steve Teare
master alchemist
Palouse, Washington
March 2026